Behind the Scenes#
In this section, we explore the design of Grain. The following diagram
illustrates the data flow within Grain. Parent process (where user creates the
DataLoader object) is highlighted in blue while the child processes are
highlighted in green.
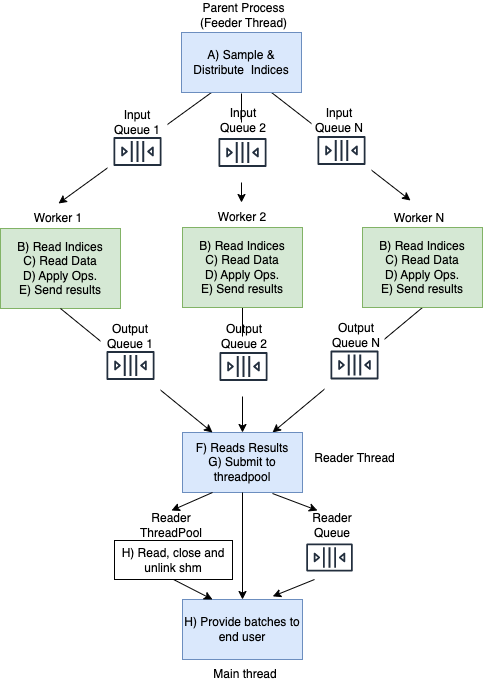
A. Parent process launches the Feeder thread. The Feeder thread iterates through the sampler and distributes
RecordMetadataobjects to input queues of the child processes (each child process has its own dedicated queue). Parent process also launchesnum_workerschild processes.B. Each child process reads
RecordMetadataobjects from its respective input queue.C. Each child process reads the data record (corresponding to
record_keysfrom theRecordMetadataobjects) using the data source.D. Each child process applies the user-provided Operations to the records it reads.
E. Each child process sends the resulting batches via its dedicated output queue (offloading sending NumPy Arrays/ Tensors to shared memory blocks.)
F. The reader thread in the parent process gets the output batches from the output queues of the child processes (going through the child processes output queues in a round-robin fashion.)
G. The reader thread submits the batches it read to the reader thread pool to asynchronously post process them (copy data out of shared memory blocks, close and unlink shared memory blocks.) An
AsyncResultfor the computation happening in the reader thread pool is put into the reader queue (to ensure results ordering.)H. When the end user requests the next element, the main thread gets the
AsyncResultfrom the reader queue and waits for the result to be ready. It then provides the result to the end user.
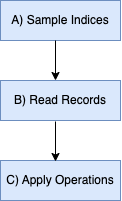
Note that the diagram above illustrates the case when num_workers is greater
than 0. When num_workers is 0, there are no child processes launched. Thus the
flow of data becomes as follows:
The Need for Multiprocessing#
In CPython, the global interpreter lock, or GIL, is a mutex that protects access to Python objects, preventing multiple threads from executing Python bytecode at once. This is necessary mainly because CPython’s memory management is not thread-safe.
The GIL is released in case of an I/O operation, or if an operation calls a C-extension that releases the GIL. However, in the case of CPU intensive python workloads, the GIL prevents taking advantage of the multiple cores available on the machine. Multiprocessing solves this problem as different processes are able to run on different CPU cores.
Communication between processes#
Each child process has its own memory space and thus by default processes can’t access each other’s objects. Typically, the communication between processes occurs via multiprocessing queues. Multiprocessing queues offer nice synchronisation mechanisms to communicate between processes, for example keeping elements ordered, controlling the number of elements to be buffered and keeping the synchronisation between producer/ consumer in case the queue is full/empty.
Determinism#
One of the core requirements of Grain is determinism. Determinism involves producing the same elements in the same ordering across multiple runs of the pipeline.
In the design above, we made the the following decisions to ensure determinism:
A. We provide the IndexSampler which ensures deterministic ordering of
elements for a given seed.
B. The feeder thread iterates through the sampler and shares with each child process the record keys to process (via the child processes input queues.)
C. Each child process iterates through record metadata in order, reads the elements and applies the operations to them.
D. Parent process iterates through the child processes in a strict round robin ordering (no skipping of processes).
As an example, suppose we have a dataset with 8 records, and we apply
shuffling to it. The Sampler might produce something like the following (we omit
index and rng for brevity and show only the record keys):
record keys: [5, 2, 0, 4, 6, 1, 7, 3]
Having 2 processes [P0, P1], each will get the following records keys:
P0gets records keys:[5, 0, 6, 7]P1gets records keys:[2, 4, 1, 3]
P0 and P1 read records with their assigned record keys, apply
transformations to them, and add them to their respective output queues. The
parent process goes through the output queues for the child processes P0 and
P1 in a strict round-robin fashion. Assuming we apply a map operation + a
batch operation (batch_size = 2), the final ordering of the elements would be
[[5, 0], [2, 4], [6,7 ], [1, 3]].